Thread 이해하기
OS: Thread
Overview
첫번째 주제는 Thread로, Thread의 개념 및 개발 시 신경써야 할 특징들에 대해서 알아볼 것입니다. 보통 Thread 실습 시 C언어를 사용하지만, 이번 Sample Code는 저희 그룹의 주력 언어인 JAVA를 사용할 것입니다. 기본적으로 Thread는 Process에 대한 이해가 필요하기 때문에 Process 선행학습 역시 포함되어 있습니다.
Contents
-
Process
1-1. Process란 무엇인가?
1-2. Process Address Space
1-3. Process Life Cycle
1-4. Process Scheduling
1-5. fork() -
Thread
2-1. Thread가 필요한 이유?
2-2. Multi Thread
2-3. Sample Code -
Synchronization(동기화)
3-1. 동기화가 필요한 이유?
3-2. Critical Section Problem
3-3. Semaphores / Mutex
Process
- Process란 무엇인가?
- 현재 실행중인 프로그램
- PCB(Process Control Block)을 가진 프로그램
※ PCB란 PID, 프로세스 상태, 프로세스 우선순위, Program Counter, Register 등 프로세스 실행에 필요한 구조체 - RAM에 올라온 프로그램
- CPU를 할당받는 실체
- Process Address Space
- 프로세스는 단순한 프로그램 이상의 정보를 갖는다.
- 메모리 상의 프로세스
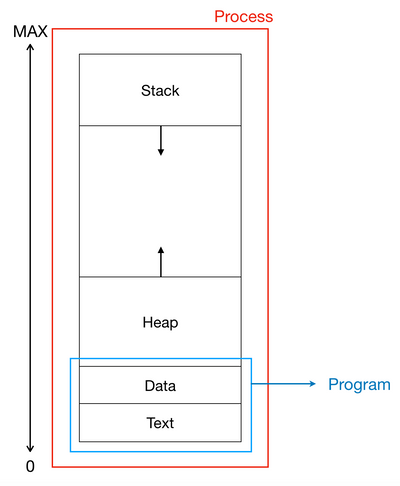
[그림 1] Process 메모리 구조 - 동적으로 변하는 영역
Stack: 로컬변수, 인자(Params/args)
Heap: 동적할당 메모리 - 프로그램 영역
Data: 전역변수, Static 변수
Text: Program code
- Process Life Cycle
- 프로세스는 메모리에 올라온 순간부터 다음과 같은 생명 주기를 거친다.
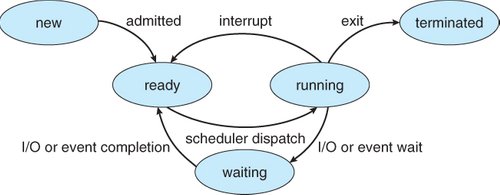
[그림2] Process 생명주기
- 프로세스는 메모리에 올라온 순간부터 다음과 같은 생명 주기를 거친다.
-
Process Scheduling
한정된 메모리, CPU 성능으로 한번에 하나의 Process만을 실행할 수 없었던 과거 컴퓨팅 환경이, 기술 발전에 따라 Multi Process 환경으로 전환됨으로써 Process의 실행 순서를 결정하는 것이 주요 이슈로 떠올랐다.※ Context Switch : 실행중인 프로세스에서 다른 프로세스로 전환하는 과정 : Context Switch는 시간이 오래 걸리기 때문에 오버헤드를 줄이는 것이 주요 이슈 : 이는 스케쥴링 알고리즘을 활용하여 해결한다.- 프로세스 스케쥴링은 크게 선점(preemptive), 비선점(non-preemptive) 방식으로 나뉜다.
-
- Preemptive
- 순서에 관계 없이 우선순위에 따라 프로세스를 실행하는 방식
- 우선순위에 밀려 wating 상태로 지속되는 프로세스가 발생할 수 있다.(Starvation)
- CPU를 점유중인 task가 있어도 우선순위가 높은 task가 발생하면 CPU는 하던 작업을 멈추고 우선순위가 높은 task를 실행한다.
-
- Non-preemptive
- 정해진 순서에 따라 task를 실행한다.
- 자원의 활용성(Utillization) 측면에서 비효율적이다.
-
- 대표적인 스케쥴링 알고리즘
-
- FCFS(First Come First Served)
- task가 메모리에 로드(task 발생) 순서에 따라 실행
-
- SJF(Shortes Job First) / SRJF(Shortest Remaining Job First)
- CPU burst time(쉽게 말하여 수행 시간)이 짧은 순서로 실행한다. SRJF의 경우 선점 SJF로, task 발생 시점을 기준으로 현재 실행중인 프로세스의 남은 수행시간과 비교한다.
- 현실적으로 CPU burst time을 예측하는 것은 불가능.
-
- Priority Scheduling (우선순위 기반 스케쥴링)
- 철저하게 우선순위에 따른 task 실행
- Starvation 발생
-
- Round Robin Scheduling
- Time Quantum을 기준으로 task를 순차적으로 실행한다.
-
- Multi-level Queue
- Ready 큐를 여러개로 분할하여 각 큐마다 자신만의 Scheduling 방식을 갖는다.
-
- 프로세스 스케쥴링은 크게 선점(preemptive), 비선점(non-preemptive) 방식으로 나뉜다.
-
fork() - Process의 생성
프로세스는 시스템콜 fork()를 호출하여 부모 프로세스는 상속하여 생성한다. 부모 프로세스는 상복받기 때문에 생성된 프로세스들은 tree 형태를 갖는다. 우리가 사용하는 운영체제는 최초의 프로세서 init이 존재-커널에서 생성-하여 init 프로세스를 상속함으로써 프로세스를 생성한다.
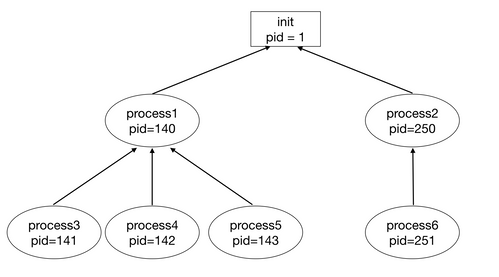
[그림3] fork()로 생성된 프로세스의 tree 구조- fork()
- 부모와 자식은 일반적으로 file을 공유한다.
- 하지만 독립된 Process이기 때문에 CPU / MEM은 별도로 사용한다.
- 기본적으로 부모의 주소공간은 복사하기 때문에 처음 fork 시 부모와 동일한 프로그램을 실행한다.
- 부모와 다른 프로그램을 실행하기 위해서는 자식은 새로운 프로그램을 로드하는 시스템콜을 호출해야 한다. (execlp)
- fork()를 호출한 부모는 자식이 종료되어 자식 프로세스의 리소스 반환을 기다려야 한다.
-> Zombie process, Orpahn process 등이 이와 관련된 주요 issue.
- Sample Code
int main() { pid_t pid; // fork another process pid = fork(); if(pid < 0){ // error occured fprintf(stderr, "Fork Failed"); exit(-1); } else if(pid == 0){ // child process execlp("/bin/pwd", "pwd", NULL); } else{ // parent process wait(NULL); printf("Child %d process complete", pid); exit(0); } }
- fork로 생성된 자식 프로세스는 부모 프로세스와 동일한 코드를 수행한다.
- 자식 프로세스가 새로운 프로그램을 실행하기 위해 새로운 프로그램으로 로드한다.
- 해당 샘플에서는 pwd 명령어를 실행한다.
- 부모 프로세스는 자식프로세스가 종료하여 리소스를 반환할 때까지 대기한다.
- 부모 프로세스가 자식프로세스의 리소스 반환을 받을 않으면 자식프로세스는 프로그램이 종료되었음에도 프로세스를 종료하지 못하는 Zombie Process로 남게된다.
- 만약 자식프로세스가 종료되기 전에 부모프로세스가 종료되었을 경우 Orphan Process로 남게 된다.
- Orpahn Process의 경우 init process에서 부모프로세스를 새로 할당한다.
- fork()
Thread
프로세스 내부의 실행흐름.
- Thread가 필요한 이유?
- Process는 독립된 개체로서 별도의 자원을 사용한다.
- 이는 context switching 시 많은 오버헤드를 발생한다.
- 이를 해결하기 위한 방법으로 Thread를 사용한다.
- Example: Web server Case
- Process
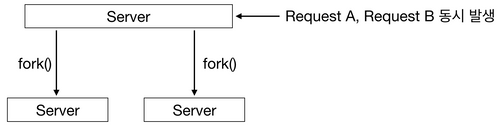
[그림 4] Request 동시처리 - Process Case- 요청을 처리하기 위해 요청의 갯수만큼 Process를 생성하는데 이는 불필요한 비용이 발생한다.
- Thread
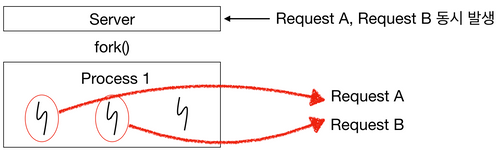
[그림 5] Request 동시처리 - Thread Case- Thread는 프로세스의 자원을 공유하여 두개의 요청을 동시 처리한다.
- Process
- Multi Thread
- Multi Thread는 Multi Process와 비교하여 다음과 같은 장점을 갖는다.
- 응답시간이 빠르다.
- 프로세스의 자원을 공유하기 때문에 오버헤드가 작다.
- Context Switching에 드는 비용이 적게 든다.
- Thread Handling
쓰레드 역시 시스템콜(메소드)를 호출하여 생성하여 프로그램을 실행한다. 그렇다면 프로그램을 실행할 때 마다 실행할 프로그램의 갯수만큼 쓰레드를 생성해야 하는 것일까? 그렇지 않다. 물론 프로그램 실행에 문제는 없지만 이러한 방법은 프로세스의 자원을 공유하는 쓰레드 특성으로 인해 성능상 한계가 오기 때문이다. 멀티쓰레드 환경에서는 Thread Pool을 사용하는 것이 일반적이다.-
- Program 갯수 마다 Thread를 생성
- 한정된 자원
- Thread 생성에 소모하는 자원 낭비
-
- Thread Pool
- 미리 생성한 Thread를 할당(비용 절감)
- 한정된 자원 안에서 해결
-
- Multi Thread는 Multi Process와 비교하여 다음과 같은 장점을 갖는다.
- Sample Code
JAVA는 기본적으로 Multi Thread를 지원한다.
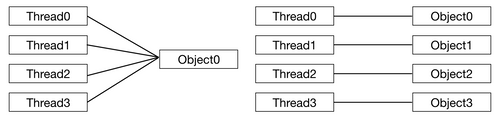
- 하나의 객체를 n개의 Thread가 공유하는 방식(implements Runnable).
- 객체 하나당 하나의 Thread가 존재하는 방식(extends Thread).
-
task별 Thread 생성.
public class ExtendsThread extends Thread { @Override public void run(){ SimpleDateFormat dateFormat = new SimpleDateFormat("dd-MM-yyyy MM:mm:ss"); String tName = Thread.currentThread().getName(); Long threadId = Thread.currentThread().getId(); for(int i = 0; i < 10; i++){ System.out.println(i + " [" + dateFormat.format(System.currentTimeMillis()) + "]" + tName + "::::[ThreadId]::" + threadId); try{ Thread.sleep(1000); }catch(Exception e){ e.printStackTrace(); } } } }Thread Class를 상속하여 생성한 쓰레드는 그 자체로 쓰레드 객체이다.
public class ImplementsRunnable implements Runnable{ @Override public void run() { SimpleDateFormat dateFormat = new SimpleDateFormat("dd-MM-yyyy MM:mm:ss"); String tName = Thread.currentThread().getName(); Long threadId = Thread.currentThread().getId(); for(int i = 0; i < 10; i++){ System.out.println(i + " [" + dateFormat.format(System.currentTimeMillis()) + "]" + tName + "::::[ThreadId]::" + threadId); try{ Thread.sleep(1000); }catch(Exception e){ e.printStackTrace(); } } } }Runnalbe Interface를 구현하여 생성한 쓰레드는 Thread 객체 생성자의 인자로 전달되어 쓰레드 객체로 사용한다.
public class Main { public static void main(String[] args){ ImplementsRunnable implementsRunnable = new ImplementsRunnable(); Thread imlRunnable = new Thread(implementsRunnable, "implementsRunnalbe"); imlRunnable.start(); ExtendsThread extendsThread = new ExtendsThread(); extendsThread.setName("extendsThread"); extendsThread.start(); } }위 샘플 코드를 실행하면 다음과 같은 결과를 얻을 수 있다.
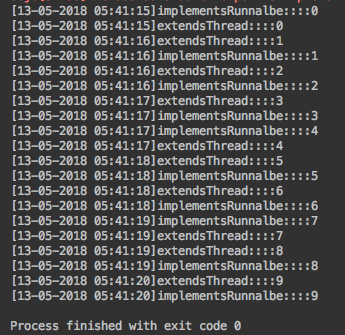
-> 실행 결과를 보면 서로 다른 두개의 Thread가 같은 시간에 실행 됨을 알 수 있다.
-> Runnable Interface를 상속받은 객체는 별도의 Thread를 통해 실행된다.
-> Thread Class를 상속받은 객체는 그 자체로 Thread이다. - Thread Pool
- 다중 쓰레드 환경에서 쓰레드는 어떻게 생성할까? 위 예시 처럼 Task별로 Thread를 할당할 것인가?
- 앞서 설명한 바와 같이 이러한 환경에서는 Thread Pool을 사용하는 것이 효과적이다.
- Thread Pool이란 미리 생성한 Thread들의 집합으로, Thread를 생성할 때 소비되는 불필요한 비용을 절감할 수 있다.
- 물론 Task의 수를 고려하지 않고 무작정 Thread Pool의 사이즈를 크게 할 경우 불필요한 메모리 낭비를 발생할 수 있으며, 노는thread 가 발생할 수도 있다.
- 다음은 10개의 Runnable task에 대해 사이즈 3의 Thread Pool이 10개의 Task를 실행하는 샘플코드이다.
public class RunnableForThreadPool implements Runnable{ private int nTask; public RunnableForThreadPool(int nTask){ this.nTask = nTask; } @Override public void run() { SimpleDateFormat dateFormat = new SimpleDateFormat("dd-MM-yyyy MM:mm:ss"); String tName = Thread.currentThread().getName(); Long threadId = Thread.currentThread().getId(); for(int i = 0; i < 2; i++) { System.out.println("TaskNumber:" + this.nTask + " [" + dateFormat.format(System.currentTimeMillis()) + "]" + tName + "::::[ThreadId]::" + threadId + "::LOOP-" + i); } } }public class Main { public static void main(String[] args){ // Thread Pool ExecutorService executorService = Executors.newFixedThreadPool(3); // MAX Thread number: 3 // Execute 10 implementsRunnable by executorService for(int i = 0; i < 10; i++){ RunnableForThreadPool runnableForThreadPool = new RunnableForThreadPool(i); executorService.execute(runnableForThreadPool); try{ Thread.sleep(500); }catch(Exception e){ e.printStackTrace(); } } executorService.shutdown(); } }위 샘플 코드를 실행하면 다음과 같은 결과를 얻을 수 있다.
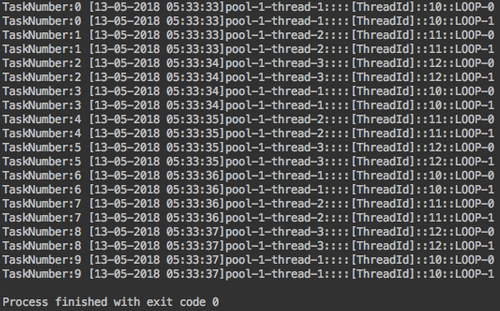
-> 위 샘플 Thread Pool의 사이즈는 3으로 지정했다.
-> 실행 결과를 보면 10개의 task에 대하여 단 3개의 Thread가 실행되고 있음을 알 수 있다.
Synchronization
- Motivation
100만원이 예금된 계좌가 있다. 여기서 A는 10만원을 출금하고, B는 5만원을 입금하려 한다. A와 B의 작업이 완료되면 계좌에 95만원이 있어야 하지만 동기화를 하지 않으면 다음과 같은 문제가 발생할 수 있다.
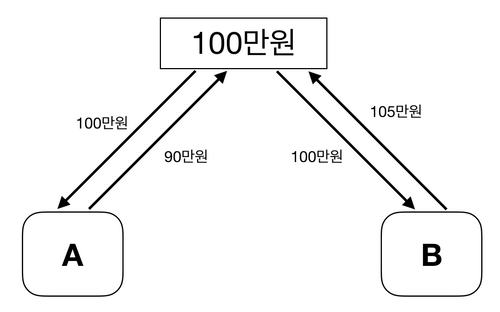
[그림 6] 동기화를 하지 않은 계좌의 문제점-
A, B가 동시에 계좌에 접근하여 입출금을 했을 때 A는 90만원, B는 105만원이 예금된 계좌를 반환한다. 이러한 문제를 해결하기 위해 Multi Process/Thread 환경에서 동기화를 사용한다.
- Critical Section Problem
- Process/Thread가 동시에 접근하는 영역(리소스)를 Critical Section(임계영역)이라 한다.
- Critical Section Problem을 해결하기 위해서는 다음 세가지 조건을 만족해야 한다.
-
- Mutual Exclusion
- Critical Section에는 오직 하나의 Process 접근을 허용한다.
-
- Progress
- Critical Section은 언제나 점유되어 있어야 한다.
-
- Bounded Wait
- 프로세스가 임계구역에 접근하기 위해 대기하는 횟수는 제한되어야 한다.
- 우선순위에 밀려 특정 프로세스를 실행하지 못하는 현상(starvation) 해결
-
- Critical Section Problem을 해결하기 위한 메커니즘
- Semaphore, Mutex(Binary semaphore - 0/1)
- 프로세스를 실행하기 위한 일종의 Flag라 할 수 있다.
- Integer로 표현한다.
- 임계영역 접근 시 Mutex를 변경하여 임계구역이 점유되었음을 표시한다.
- Process 종료 시 다시 Mutex를 변경하여 임계구역이 free임을 표시한다.
- C에서는 Mutex, Semaphore 자료구조를 라이브러리로 제공하고 있으며, JAVA에서는 synchronized 키워드로 동기화를 구현한다.
- 임계영역과 세마포어를 쉽게 설명하기 위해 임계영역은 화장실, 세마포어는 화장실의 열쇠로 많이 비유한다.
- Sample Code
- JAVA는 synchronized 키워드를 붙여 사용한다.
- 한 Thread가 synchronized 블럭에 들어가면 해당 객체 전체에 lock이 걸려, synchronized 블럭을 벗어날 때까지 다른 쓰레드들은 이 객체에 접근할 수 없다.
- 해당 sample code는 MethodSync라는 객체의 test 메소드에 동기화를 해준 상태이다.
public class MethodSync { private String curDate; private String tName; public MethodSync(String curDate, String tName) { this.curDate = curDate; this.tName = tName; } public synchronized void test(){ for(int i = 0; i < 5; i++) { System.out.println("[" + curDate + "] " + tName); } } } - Runnable 객체에서 동기화하는 메소드를 호출한다.
public class ImplementsRunnable implements Runnable{ @Override public void run() { SimpleDateFormat dateFormat = new SimpleDateFormat("dd-MM-yyyy MM:mm:ss"); String tName = Thread.currentThread().getName(); MethodSync methodSync = new MethodSync(dateFormat.format(System.currentTimeMillis()), tName); methodSync.test(); } } -
Main에서는 3개의 쓰레드로 동기화된 메소드 MethodSync.test()를 호출한다. 실행결과는 다음과 같다.
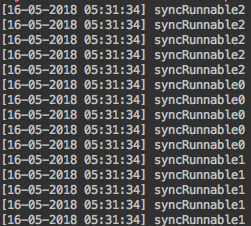
동기화 한 메소드 test()가 종료 되서야 다음 쓰레드가 수행 됨을 확인할 수 있다. - 만약 synchronized 키워드를 뺀다면 다음과 같은 실행 결과를 얻는다.
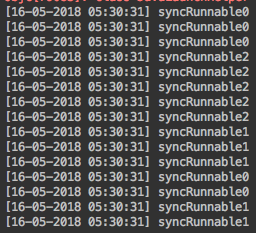
동기화를 하지 않으면 메소드가 실행중임에도 다른 쓰레드에서 동시에 실행된다.
-
댓글남기기